Can you see the trees?
Hint: increase the brightness and look closely.

Our monocular model outputs robust depth estimates in all conditions, even in the dark.
Hint: increase the brightness and look closely.
Our monocular model outputs robust depth estimates in all conditions, even in the dark.

While state-of-the-art monocular depth estimation approaches achieve impressive results in ideal settings, they are highly unreliable under challenging illumination and weather conditions, such as at nighttime or in the presence of rain. Noise, dark textureless areas, and reflections are detrimental factors that violate the training assumptions of both supervised and self-supervised methods. While self-supervised works cannot establish the pixel correspondences needed to learn depth, supervised approaches learn artifacts from the ground truth sensor (LiDAR is shown in the figure above with samples from nuScenes).
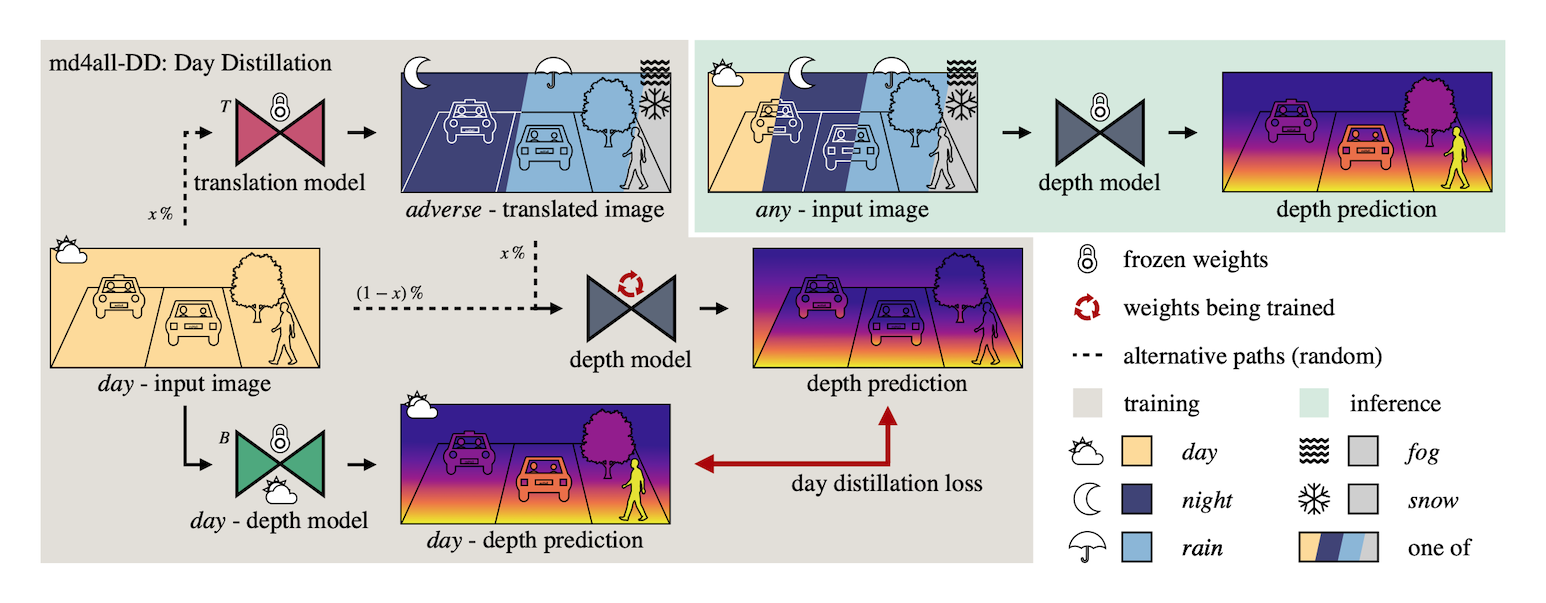
In this paper, we tackle these safety-critical issues with md4all: a simple and effective solution that works reliably under both adverse and ideal conditions, as well as for different types of learning supervision. We achieve this by exploiting the efficacy of existing methods under perfect settings. Therefore, we provide valid training signals independently of what is in the input. First, with image translation, we generate a set of complex samples corresponding to the normal training ones. Then, we train the depth model by guiding its self- or full-supervision by feeding the generated samples and computing the standard losses on the corresponding original images. As shown in the figure above, we take this further by distilling knowledge from a pre-trained baseline model, which infers only in ideal settings while feeding the depth model a mix of ideal and adverse inputs. Our GitHub repository contains the implementation code of the proposed techniques.

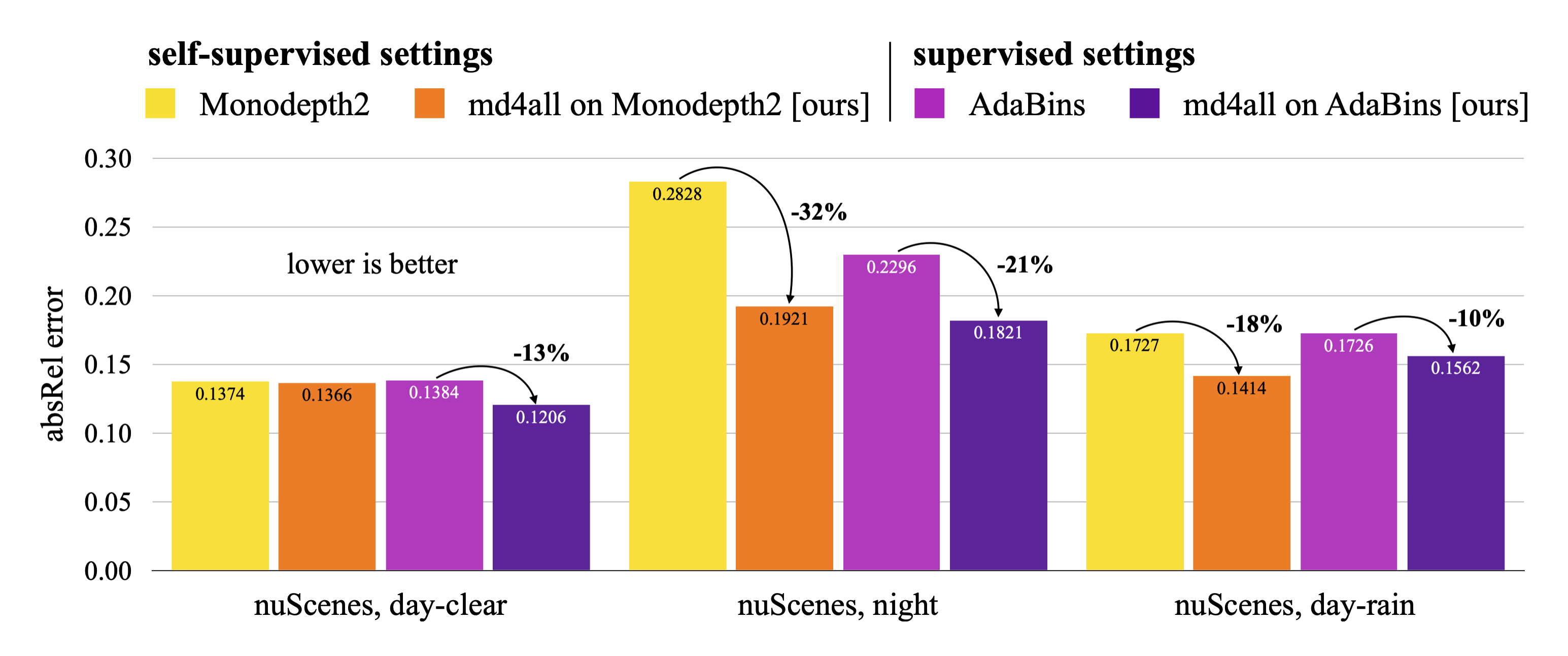
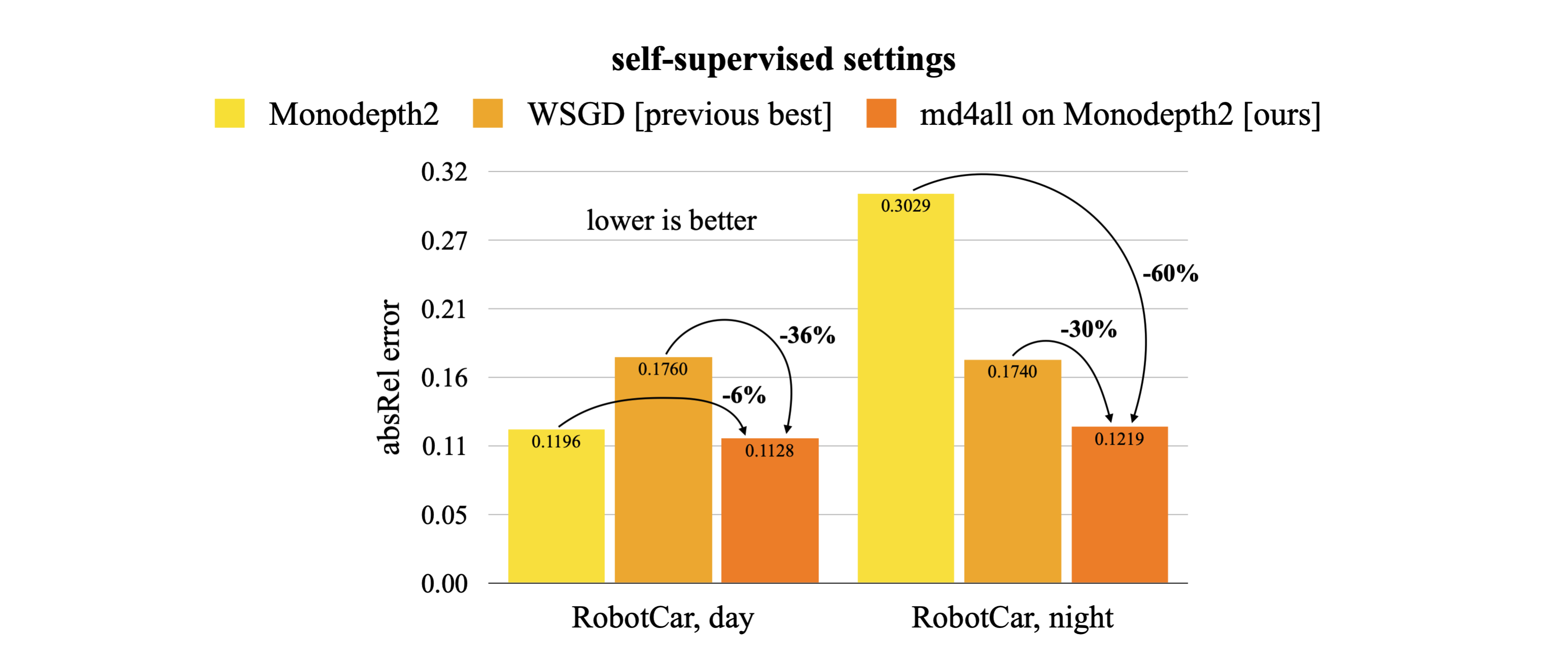
With md4all, we substantially outperform prior solutions, delivering robust estimates in various conditions. Remarkably, the proposed md4all uses a single monocular model and no specialized branches. The figure above shows predictions in challenging settings of the nuScenes dataset. The self-supervised Monodepth2 cannot extract valuable features due to darkness and noise (top). The supervised AdaBins learns to mimic the sensor artifacts and predicts holes in the road (bottom). Applied on the same architectures, our md4all improves robustness in both standard and adverse conditions.
The figure above shows examples of the image translations generated to train our md4all. Our method acts as data augmentation by feeding the models with a mix of original and translated samples. This enables a single model to recover information across diverse conditions without modifications at inference time. Here, we share open-source all images in adverse conditions generated to correspond to the sunny and cloudy samples of nuScenes and Oxford Robotcar training sets. These images can be used for future robust methods for depth estimation or other tasks.
@inproceedings{gasperini_morbitzer2023md4all,
title={Robust Monocular Depth Estimation under Challenging Conditions},
author={Gasperini, Stefano and Morbitzer, Nils and Jung, HyunJun and Navab, Nassir and Tombari, Federico},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2023},
pages={8177-8186}
}